



小規模AIモデルの意外な可能性

目次
要点
- これまで、注目は主にOpenAIやAnthropicなどの著名なAI研究所や、Nvidiaなどのハードウェアメーカーを含むAIスタックの下層に集まっていました。
- スタックの下層に対する注目と資本の集中は、アプリケーション層で蓄積されている潜在的な可能性を見落とす結果となっています。
- 今後数か月の間に、アプリケーション層での実験が進むにつれて、AIモデルをアプリケーションに統合する開発者は、特定の機能に特化したものを含む比較的小規模のモデルを使用することで、より管理しやすく柔軟なAIシステムを構築できることに気づくかもしれません。
- 小規模AIモデルの利用は、分散型トレーニング、ローカル推論、データセットの収集や作成といった、AI x クリプトスタック内の多くの分野において良い影響をもたらすと考えられます。
2022年末にタイムスリップしてみましょう。世界は初めて、OpenAIのchatGPTに組み込まれた魔法のような機能を体験していました。当初の実験の多くは、新しいけれども変革的な技術にありがちなパターンに従っており、主に「楽しいおもちゃ」として扱われました。
それから現在に飛び、chatGPTが引き起こした火花は、最初の汎用人工知能(AGI)の開発を目指して、莫大な資金を集める全面的な競争へとつながりました。その最終目標を念頭に、注目はすべて、次の数兆パラメーターの最先端モデルや、ハードウェアを開発する大規模なAIラボ(例:OpenAIやAnthropic)やNvidiaのようなハードウェアメーカーに向けられています。
AIラボとハードウェア企業は、AIスタックの下層を構成しており、これらが結合して、AIエージェントやアプリケーション、システムが生まれるための基盤となります。スタックの下層に対する注目と資本の集中は、アプリケーション層で進行中の潜在的な可能性を見落とす結果となっていました。比較的シンプルなAIエージェントであるchatGPTが示したように、これらのモデルから生まれる本当の魔法は、他のソフトウェアシステムと統合され、統一的な製品を生み出すときに実感されるのです。
より一般的に言えば、純粋なAIモデルとツール、オーケストレーションソフトウェア、ビジネスロジック、さらには追加のAIモデルを組み合わせたアプリケーションは、AIシステム、もしくはバークレーAIリサーチグループが名付けた「複合AIシステム」と呼ばれます。彼らが指摘するように、これらのシステムは、単一のAIモデルでは達成できない優れた成果を生み出すことができます。
より多くの開発者がAIモデルをアプリケーションに統合する実験を行う中で、特定の機能に特化したものを含む比較的小規模のモデルが、より管理しやすく柔軟なAIシステムを構築する可能性があります。コスト削減だけでも、小規模モデルの利用を検討する魅力的な理由となります。例えば、OpenAIの大規模なGPT-4oモデルの利用は、GPT-4oミニモデルの約30倍のコストがかかります。
小規模モデルの使用が増え続ける世界は、分散型モデルトレーニング、ローカルな推論、データ収集のインセンティブ化といった、AI x クリプトスタック内で多くのチームが注目している分野において、好ましい二次的な効果をもたらす可能性があります。
AIシステムと小規模モデル
上述したAIシステムへの移行は、スタンドアロンのAIモデル使用の自然な進展です。一般的に、AIモデルそのものはエンドユーザーが求める最終製品ではありません。むしろ、価値を生み出すのは、ソフトウェアシステム全体(つまり、AIアプリケーション)です。
通常のアプリケーション開発と同様に、AIモデルや複数のモデルをビジネスロジックや必要なツールと一緒にパッケージ化するには、慎重な設計と、おそらく多くのテストサイクルや反復、デプロイが必要です。この点から、小規模で特化したモデルは、アーキテクチャの観点からより有利になる可能性があります。
小規模AIモデルの利点
これまでのところ、大規模言語モデル(LLM)のスケーリング法則は成り立っています。モデルの全体サイズ、計算コスト、トレーニングデータセットのサイズを増やすことで、より高性能、つまり「より知的な」モデルが生み出されてきました。しかし、ますます大型化するモデルの性能向上には、小規模なモデルに比べてトレードオフも伴います。
モデルのトレーニングと推論のトレードオフ
小規模モデルは、最先端の大規模言語モデル(LLM)に比べて、より短時間で、軽い計算リソースでトレーニングすることができます。たとえば、スケーリングの極限に向かう例として、MetaのLlama 3.1モデル群は、15兆以上のトークンを含む膨大なトレーニングデータセットを活用し、NvidiaのH100 GPUの高度なクラスターと組み合わせてトレーニングされました。Metaの16,000台のH100を使用した最も大きなモデルのトレーニングには、おそらく数週間から数か月かかったと考えられます。一方で、小規模モデルは、より少ないGPUで、より短い時間で、少ないデータ量でトレーニングが可能です。迅速な製品開発とデザインの反復に注力するアプリケーション開発者にとって、アプリ内で狭い範囲の機能しか必要としない小規模モデルは、魅力的な選択肢となります。
モデルの推論とは、トレーニングされたモデルをアプリケーションに統合し、実際にクエリを実行することを指します。モデルの応答時間(レイテンシー)は、AIアプリケーションが運用され、実際のユーザーリクエストに対応する際の重要な指標です。可能な限り低いレイテンシーを実現することは、全体的なUXの向上につながります。もしchatGPTが各クエリに対して数分、あるいは数十秒かかって応答するとしたら、UXは非常に悪く感じられるでしょう。小規模モデルでは必要とされる計算リソースが少ないため、大型モデルに比べて推論リクエストの処理がより速く行えます。
これらの設計上の選択が、アプリケーション開発者が対処しなければならないトレードオフの空間を形成します。モデルをどこまで小型化しても、アプリケーションの要件(レイテンシーやコスト)を満たすパフォーマンスを維持できるかが問われます。
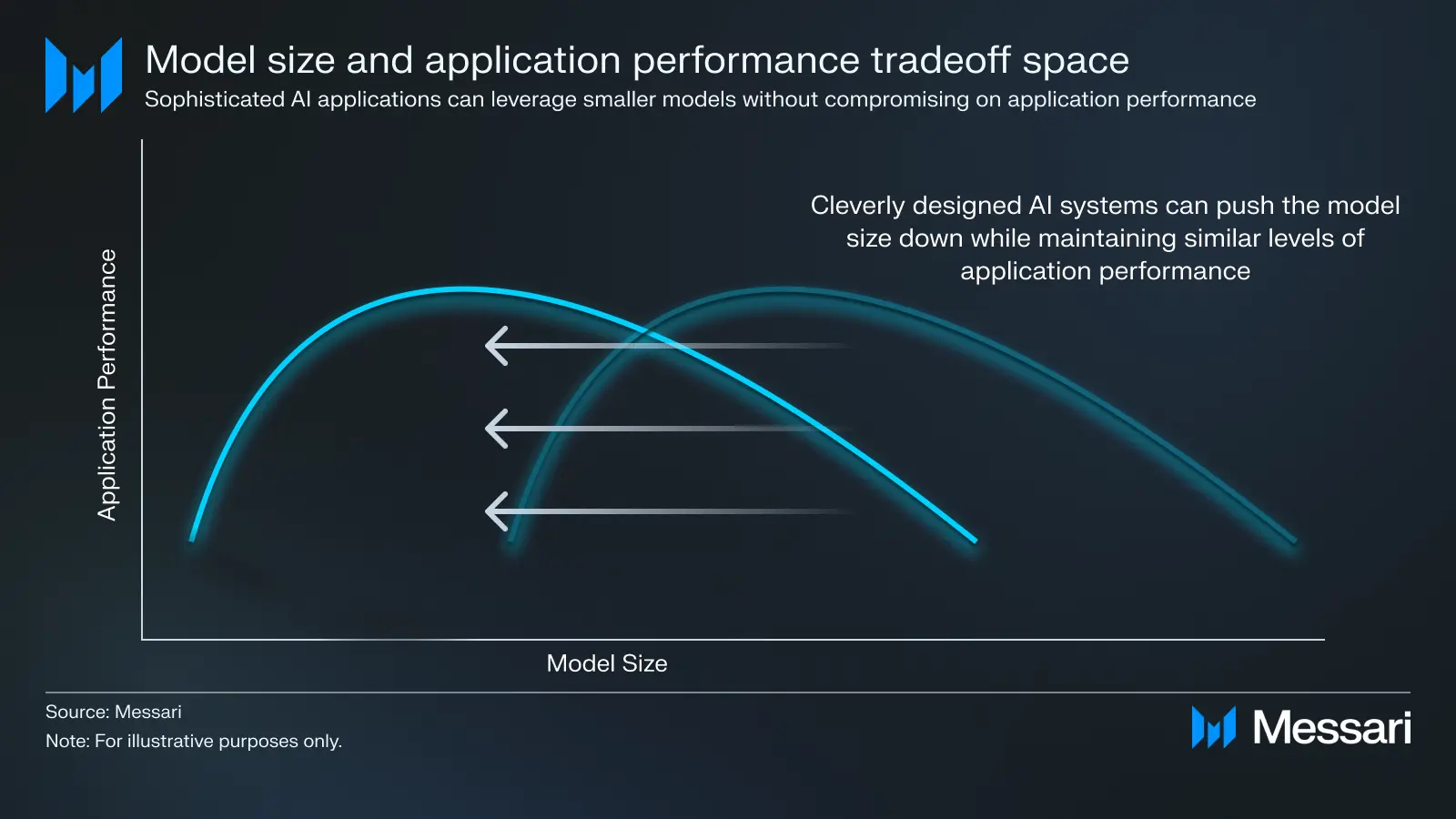
これまで、開発者が大幅なパフォーマンス向上を目指す最適な選択肢は、次世代の大規模な最先端AIモデルの登場を待つことでした。これらのますます大型化するモデルは、より多くの機能を実現するという期待に応えてきましたが、その分、計算リソースとレイテンシーのコストが増大していました。多くの人にとって、これらの巨大なモデルに依存することが、理想とするアプリケーションのUXを実現する唯一の方法に思われました。しかし、効率の観点から見ると、このアプローチは過剰でした。すべてのアプリケーションがこれらの巨大モデルのフルパワーを必要としていたわけではなく、モデルの能力と実際のアプリケーションのニーズとの間にギャップが生じていたからです。
現在、状況は変わりつつあります。小規模のAIモデルが実際のプロダクション環境に導入できるほど十分に強力になってきました。複雑なビジネスロジックや、ツールの使用、関数呼び出し、検索強化生成(RAG)システム、ファインチューニング、さらには他の小規模AIモデルとの組み合わせといった技術を活用することで、これらのAIシステムは、大型モデルを使用する場合と同等、あるいはそれ以上の成果を上げることが可能です。
AI x クリプトへの影響
小規模AIモデルのAIシステムやアプリケーションへの導入は、分散型トレーニング、ローカル推論、インセンティブを与えたデータ収集など、AI x クリプトスタック内のいくつかの分野にとって好ましい影響をもたらします。
分散型および分散トレーニング
最近の分散型および分散トレーニングに関する突破口は、この概念を主流のAIの注目を集めるものとしました。Prime IntellectとNous Researchは、それぞれ異なる技術を用いて、地理的に分散した計算クラスターを利用したAIモデルのトレーニングの実現可能性を示しました。これらの最新発表の前は、分散型トレーニングは実際的かつ経済的に達成不可能と見なされていました。
初期の印象的な結果にもかかわらず、これらのトレーニング手法を拡張して、OpenAIやAnthropicのようなAIラボが生み出すモデルサイズ(例:数兆パラメーターのモデル)に匹敵するモデルを作成するためには、さらなる研究とエンジニアリングが必要です。
しかし、小規模モデルを活用する者(Prime IntellectとNousはそれぞれ数十億パラメーターのモデルで実験しました)は、これらの新しい分散トレーニング手法をシステムに組み込むことで、GensynやPrime Intellectのような分散トレーニングプロトコルを利用することができます。
ローカル推論
新しい生成AIモデル(テキスト、画像、動画を問わず)のほとんどのユーザーは、ホスティングサービスを通じてAIモデルを操作します。たとえば、既存の従来型クラウドアーキテクチャと同様に、OpenAIは効果的にchatGPTアプリケーションをホストし、開発者が自分のモデルセットと統合するためのAPIエンドポイントを提供しています。
ホスティングサービスがユーザーに提供する利便性は過小評価できません。しかし、欠点もあります。それは以下の通りです:
- ブラックボックスモデル – 今日使用しているモデルは、明日には変わってしまう可能性があります。ユーザーの観点から見ると、それはブラックボックスです。サービスプロバイダーは、ユーザーが気づかないうちにモデルを切り替えることができます。これにより、予期しない動作が生じたり、高品質なモデルの代わりに低品質なモデルが置き換えられることがあり、高品質なモデルに対して支払ったにもかかわらず、質が低下する可能性があります。
- プライバシー – サービスを運営するエンティティは、モデルを通じて送信されるすべてのデータを見ることができます。これにより、ユーザーはクエリをプライベートに保つことができなくなります。
Exo Labsチームは、ユーザーがオープンソースモデルをローカルデバイス(例:ノートパソコンやスマートフォン)で実行できる使いやすいSDKを作成することで、これらの問題に取り組んでいます。一般的に、電話のようなローカルエッジデバイスは、AIモデルなどの計算負荷の高いソフトウェアを実行するための必要なハードウェアを欠いています。Exo LabsのSDKは、複数のデバイスを接続して、単一の、より高機能なハードウェアとして機能させるのに役立ちます。クリプトの観点から見ると、ローカルモデルはオンチェーンのスマートコントラクト操作をトリガーするように設定できます。
最も高性能なGPUのパワーにはまだ及びませんが、このタイプのソフトウェアはユーザーが自分のデバイス上で小規模のオープンソースモデルを実行できるようにします。シンプルなAIアプリケーション(例:chatGPTのようなチャットボット)の場合、これらをローカルで実行することで、上述したブラックボックスおよびプライバシーの問題を解消できます。
トレーニングデータのインセンティブと革新
データは、AIモデルの性格や一般的な行動を形成するための核心的な要素です。
例えば、Dippyを考えてみましょう。これは、character.aiに似たAIコンパニオンアプリケーションを作成しています。DippyのBittensorサブネットは、ロールプレイ用のLLMの作成にインセンティブを与え、それらをアプリケーションにさらに統合します。EQベンチマークは、ロールプレイ用LLMの質を判断するための重要な指標の一つです。これは、モデルの感情知能を測ることを試みており、AIコンパニオンにとって非常に重要です。EQベンチマークの測定に使用されるデータセットを革新することで、DippyチームはMetaやOpenAIが生み出した同規模のモデル(約70〜80億パラメーター)を上回る成果を上げました。
より広く見ると、Bittensorのようなクリプトシステムを活用して特定のデータセットを収集・作成するためのインセンティブを提供することは、新たに成長している傾向です。Dippyのサブネットの外では、Macrocosmosのsubnet13はさまざまなソースからデータをスクレイピングすることに焦点を当てています。将来的には、このサブネットの自然な拡張として、誰でもサブネットのリソースを使ってデータをスクラップしたり、他の方法で調達することができるようになるでしょう。これは、非常に特定のデータセットに依存する小規模で専門化されたモデルを活用する人々にとって魅力的な選択肢となる可能性が高く、クリプトインセンティブメカニズムがこのサブネットの運営において重要な役割を果たすことになるでしょう。
最後に
間違いなく、次のフロンティアモデル(例:GPT-5)や高性能コンピューティングチップのリリースは、引き続き一般の人々からの注目を集めるでしょう(それは当然のことです)。しかし、chatGPTのケースのように、これらのモデルの真の影響は、それらが巧妙にアプリケーションや製品に統合されたときに感じられます。
開発者が単純なチャットボット型AIアプリケーションを超えて進んでいく中で、これらのシステムに組み込まれた小規模モデルは魅力的な選択肢を提供します。これらは一般的に、より大きなモデルよりもコスト効果が高いだけでなく、モジュール式のソフトウェアとして機能することで、全体的な製品をより柔軟にします。分散型トレーニングやコンピューティングプロトコル、ローカル推論プロジェクトの開発者、データセット収集プロトコルは、これらの小規模モデルの使用が増えることで恩恵を受けることができます。
未来のある時点で、AIラボがAGIを創造し、「小規模」モデルを使用する必要がなくなるかもしれません。しかし、それまではAIアプリケーションの開発者たちは、限られたリソースでより多くのことを実現する方法を模索し続けるでしょう。
*元の記事は2024年9月6日執筆です。記事中のデータは現時点の数値と乖離している可能性がございます、予めご了承ください。