



AIとクリプトの交差点を理解する

要点
- AI xクリプト分野、すなわち分散型AIは、爆発的な成長を続けており、多くのプロジェクトが10億ドルのバリュエーションを上回っています。また、この分野で開発を行うチームに数億ドルの資金が流入しています。
- オープンソース(コードとアーキテクチャが公開済みで、誰もが自由に使用・変更・配布することが可能なAIモデル)プロジェクトは、スケールメリットの面で優位性を持つ集中型かつクローズドソースのAI企業に後れを取っています。
- 集中型かつクローズドソースのソリューションと競合する現実的な代替案を提供するためには、分散型AIチームはモデルアーキテクチャの革新とモデル調整プラットフォームの活用が必要となります。実際には、これにより、ML研究者やエンジニアは、様々なアプリケーション分野を対象とした多種多様なモデルを幅広く試すことができるようになります。これは、クリプトネットワークがAI開発を加速できることを示すものです。
- 同時に、オンチェーンアプリケーションやプロトコルは、AIエージェントを通じて、新たなオンチェーンユーザー層を獲得する可能性が高いでしょう。WayfinderやAutonolasなど、多数のチームがこの領域でプロトコルを構築しています。これらの進展は、AIがオンチェーンアプリケーションやプロトコルの成長と経済活動を加速できることを示しています。
- 今後、この分野は停滞する兆しはなく、これらの技術が互いに推進し合うことが期待されます。
はじめに
Messariは昨年3月に初めてAI x クリプト分野の台頭を取り上げました。それ以来、この分野は爆発的に成長しています。現在では多数のプロジェクトが10億ドルのバリュエーションを上回り、2024年7月だけでも2億3000万ドル近くがさまざまなAI x クリプトプロジェクトに投資されました。
どうやら、新興領域「AI x クリプト」(注:私たちは「AI x クリプト」を「分散型AI」と置き換えて使用することが多いです)プロジェクトが毎日立ち上げられているようです。多少のニュアンスの違いはありますが、大半のプロジェクトは通常、以下のように分類できます。
- 分散型コンピューティングネットワーク:これらは一般的に、モデルのトレーニング、微調整、または推論に活用できるGPUのネットワークです。
- 調整プラットフォーム:このカテゴリーは、ある程度コンピューティングネットワークと重複しています。ただし、このカテゴリーの特徴は、Bittensorが提供しているようなモデル開発のインセンティブ化、またはModulusが開発しているような専門的な推論設定(例:zkML)です。
- AIツールおよびサービス:このカテゴリーのプロジェクトは、AIモデルやエージェントが使用するサービスを運用または構築するのが一般的です。多くの場合、ツールやサービスは共有マーケットプレイス内にて販売され、AIエージェントは利用可能なサービスの組み合わせにアクセスするために料金を支払うことができます。
- アプリケーション:概念的にはchatGPTと似ており、アプリケーション層では、基盤となるAIモデルが消費者または企業向けに商品化されます。
全体的な傾向を概観すると、これらの各レイヤーの所々に可能性を見出すことができました。上述の各カテゴリーを検討する際には、AIがクリプトを補助しているのか、あるいはその逆なのかを考慮することが重要です。この視点は、AIとクリプトの交差点を捉え、定義する手段のひとつでもあります。
広い意味で、分散型AIのビジョンは、クローズドソースの集中型AIの世界と競合し、その代替手段となることです。その目的のために、AI x クリプトスタックの各カテゴリーまたはレイヤーで構築されているプロジェクトの体系的なレビューに代えて、本レポートでは、分散型AIスペースのプロジェクトが注目すべき機会・重視すべき領域をいくつか特定することを目的としています。
現状では、オープンソースのシステムがクローズドソースのAIシステムと競合するまでには至っていません。OpenAI、Claude、GoogleのDeepMindなど、クローズドソースのもとで活動するAIラボは、最先端のフロンティアモデルの水準を常に高めています。これらのラボは、web2のハイパースケーラー(Microsoft、AWS、Googleなど)と組み、巨大な規模の経済を生み出しています。業界トップクラスの人材はこれらの組織に引き抜かれ、それによって、事実上無限の資金とコンピューティングリソースが提供されます。その結果、クローズドソースのAIシステムが先頭に立ち、オープンソースモデルは後れを取っているのです。
しかし、敗北が確定している訳ではありません。
分散型AI:チャンスのある分野
ほとんどの集中型AIラボは、最大かつ最も高性能な最先端モデル(OpenAIのGPTモデルなど)の開発を主に目的としています。 ここで発生する機会費用は、さまざまなモデルアーキテクチャを幅広く実験し、迅速に調整する能力が不足してしまっていることです。 これは、さまざまな研究者やプロジェクトが各自の関心分野を探究できるという点で、分散型AIが集中型AIよりも優れていることを意味します。
この利点を活用するための重要な要素は、分散型GPUネットワーク(Akash、Prime Intellectなど)とモデル調整ネットワーク(Bittensor、Alloraなど)です。特にモデルのトレーニングと微調整に関しては、既存の(集中型の)モデルトレーニング手法は分散型コンピューティングネットワークにはうまく適合しないため、この点が重要な課題となります。AIとクリプトの融合は、クリプトネットワークがAI開発を加速させるのに役立つことを示しています。
ほとんどの消費者は、LLMベースのモデルをチャットボットやアシスタント(例:chatGPT)の形で使用しています。これらのAIシステムにさらに多くの機能やスキルを追加することで、ユーザーに代わって動的に行動できる自律エージェントに変貌します。chatGPTのような単一のエージェントに依存するのではなく、複雑な目標や目的を達成するには、専門化された、またはよりタスクに特化したエージェントが連携することが広く求められるでしょう。このような世界では、取引手段としてクリプトが好まれるでしょう。なぜなら、AIエージェントは銀行口座を開設できないからです。
ピアツーピア、あるいはエージェント間のシンプルな決済も可能ですが、オープンでパーミッションレスのネットワークを操作するには、さらなるインフラが必要です。Wayfinderは、AIエージェントが安全かつ確実に高度なオンチェーンアクション(トークン交換、ブリッジング、ステーキングなど)を実行できるプラットフォームを開発しています。AIエージェントの台頭に伴い、AIとクリプトの交差点という観点では、AIがオンチェーンアクティビティの生成を助け、それによってクリプトネットワークが進化していくと思われます。
これらの概念については、以下で詳しく説明しますが、まずはAIとMLに関する簡単な基礎知識を紹介します。
機械学習(Machine Learning)の基礎知識
サミ・カサブが指摘しているように、機械学習(ML)は、データ内のパターンを認識し、それらのパターンに基づいて予測を行うためのトレーニングアルゴリズムを扱うAIのサブ領域です。ML自体は幅広いカテゴリーですが、ここ数年、大型言語モデル(LLM)がこの分野における研究対象として成長しています。LLMは通常、ニューラルネットワークアーキテクチャを活用しており、複数の相互接続ノードの層から構成され、連携して入力データを処理し、応答を生成します。
MLモデルの開発における主要な要素は、大きく分けてアルゴリズム、データ、計算の3つに分類できます。これらのカテゴリーは、MLよりも広い領域で発生している制約や課題のいくつかと直接関係しており、その多くは本レポート全体を通して説明します。
アルゴリズム
アルゴリズムは、MLモデルのアーキテクチャの基幹を成すものであり、MLモデルが開発される数学的枠組みを表します。具体的には、アルゴリズムはモデルが従う一連のルールを定義し、最終的にモデルが処理するデータから学習することを可能にします。 アルゴリズムは、その時々のタスクに応じて真価を発揮します。
線形回帰やロジスティック回帰は、より一般的に使用されるアルゴリズムの例であり、さまざまなアプリケーションや研究分野で広く採用されています。アルゴリズム層における基礎研究は、ニューラルネットワークや、特にトランスフォーマーアーキテクチャで示されているように、MLモデル開発における画期的な進歩に直接つながる可能性があります。
例えば、2017年にトランスフォーマーアーキテクチャが導入されたことで、最終的にOpenAIの有名な生成事前学習型トランスフォーマー(GPT)モデルの開発につながりました。現在、ニューラルネットワークとトランスフォーマーアーキテクチャは、MetaのLLaMAモデルやAnthropicのClaudeモデルファミリーなど、最も著名な大型言語モデル(LLM)のいくつかを支えています。LLMの分類方法は数多くありますが、パラメータ数で分類する方法は有用です。LLMのパラメータは、モデルの全体的なパフォーマンスを向上させるために調整できる個別のユニークなチューニングノブと考えることができます。現在の最先端モデルは数百億、あるいは兆単位のパラメータを備えています。
データ
LLMなどのデータ駆動型MLモデルは、商品化や消費可能な商品へのパッケージ化の前に、膨大な量のデータでトレーニングされます。OpenAIのchatGPTは、幅広いインターネットデータや公開ウェブサイトなど、多種多様なデータに含まれる数十億単語でトレーニングされた可能性が高いです。技術的には、LLMで処理される単語やデータは、ML用語では「トークン」と呼ばれます。一般的に、トークンを単語に変換する際の目安として、1トークンは約0.75単語とされています。
LLMが質問に回答する際、本質的には、出力の次にどの単語(より厳密に言えば、どのトークン)が来るかを予測しようとしています。トレーニングデータは、LLMが単語や文字のパターンを識別するのに役立ち、最終的には、一貫性のある出力を構築するのに役立ちます。
「ゴミを入れればゴミが出る」という格言は、LLMとそのトレーニングデータにも当てはまります。LLMの開発には極めて大型のデータセットを活用できますが、高性能なLLMを構築するには、より高品質でクリーンなデータが重要な要素であると認識されています。この考え方は、Reddit、Photobucket、その他多数の企業が、膨大な量のデータを必要とする生成AI企業と数百万ドル規模の契約を結ぼうとしていることから、より明確になってきています。例えば、Reddit上のデータは、それなりの文脈があり、ある意味で厳選されたものであるため、非常に高く評価されています。
計算
モデルによるトレーニングデータの処理とその後の商品化には、通常、膨大な計算量が必要となり、その主なソースは強力なGPUです。
LLMをトレーニングする際には、通常、数十億から数兆のトークンがLLMに与えられ、これはテラバイト単位の生データに相当します。LLMがトレーニングデータを処理すると、次のトークンを予測します。LLMは、次のトークンを予測する精度に基づいてパラメータを計算し、調整します。このループは、モデルが一定の満足のいく精度に達するまで、トレーニングデータセットに対して繰り返されます。
モデルがトレーニングされると、次に、消費者によってモデルが使用されるようになります。たとえば、chatGPTやその他のチャットアシスタントに質問をして、回答を受け取るのが典型的な使用例です。モデルのトレーニングはバッチ処理と考えることができますが、モデルの推論はオンデマンドサービスに似ています。一般的に、モデルは商品化され、chatGPTなどの消費者向け商品として、またはAPI経由で使用することができます。これは、基盤となるMLモデルを自社商品に統合したいアプリケーション開発者にとって、より有益な場合があります。
AIとクリプトの交差点
上記で述べたように、AIとクリプトの交差点を考える際には、2つの関連技術の一方が他方を支援するという観点から見るのが有益です。新しいMLモデルアーキテクチャやトレーニング方法の実験は、AIシステムの成長と発展を支援するクリプトネットワークにより適合しています。一方、実用可能なAIエージェントを展開することは、より多くの経済活動をオンチェーンにもたらすのに役立ちます。
以下のセクションでは、これらの領域についてさらに掘り下げ、市場全体における注目すべきギャップを特定し、そのギャップを埋めるために各企業が今後注力すべき領域について考察します。
MLモデルのトレーニング
過去2年間、GPUや関連ハードウェアへのアクセスを獲得するために、多額の投資が実施されてきました。この点については以下で詳しく説明しますが、理由は単純明快です。資金調達 → コンピューティング能力の増強 → より優れたモデルの構築とトレーニング。現在のMLモデルのトレーニングのパラダイムは、この力学を大いに反映しています。
MLモデルのトレーニング市場の構造
OpenAIのGPTシリーズやGoogleのジェミニモデルなどのフロンティアモデルは、制作に多額の費用がかかります。
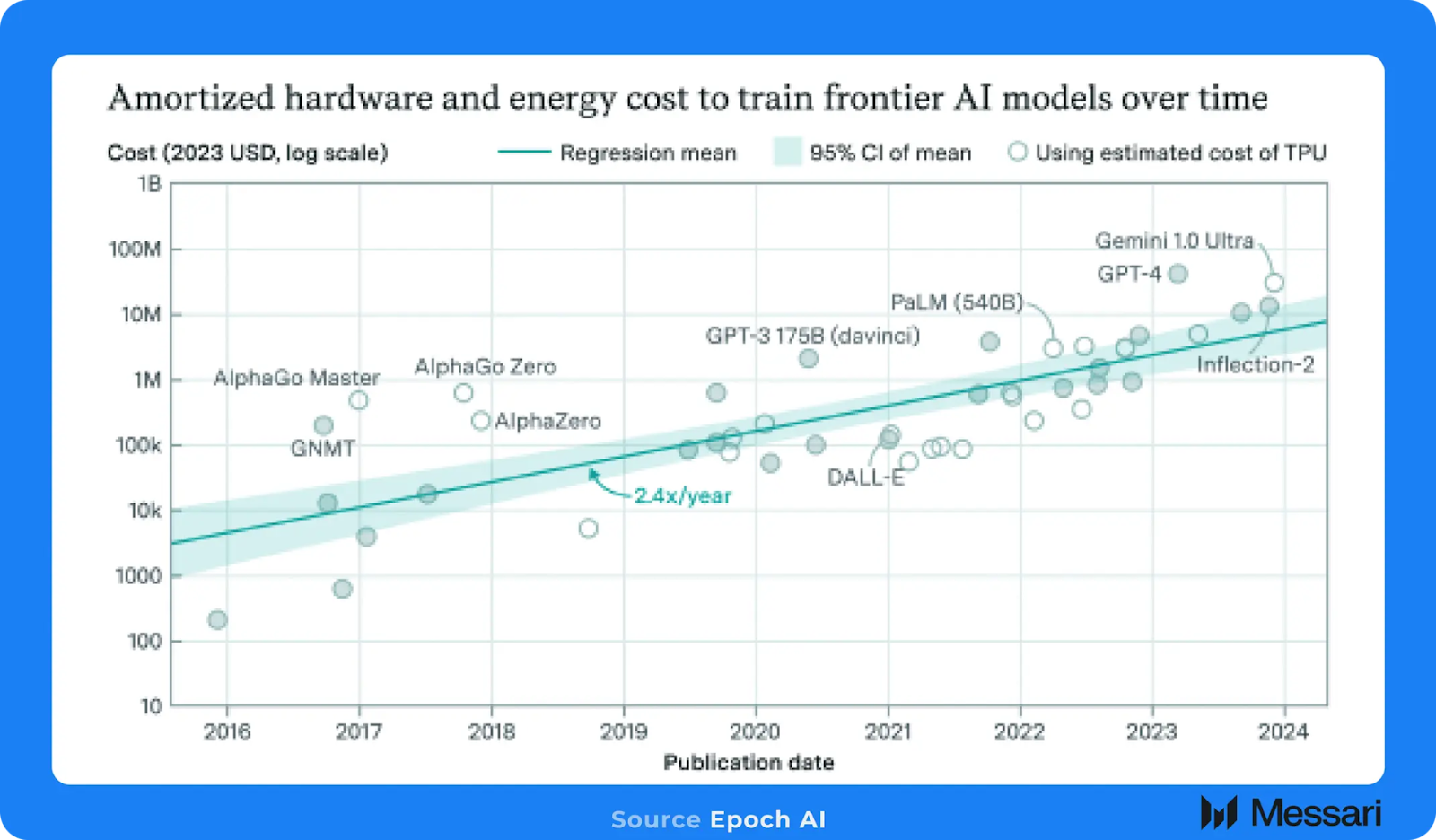
Epoch AIは、GPT-4のトレーニングには約4000万ドル相当のGPUコンピューティングが必要だったと推定しています。さらに、LLMのトレーニングにかかる費用は増加の一途をたどっており、Epoch AIは年率2.4倍から2.6倍のペースで上昇すると推定しています。この成長率から、2027年にはトップクラスの最先端モデルのトレーニングには約10億ドルのGPUコンピューティングが必要になると推測されます。したがって、モデルの開発を目指す人々にとって、大規模なGPUへのアクセスは不可欠となっています。
計算能力の拡張の必要性から、現在の機械学習モデルのトレーニングでは集中型パラダイムが採用されています。この集中型セットアップでは、トレーニングプロセスで使用されるすべてのGPUが同じデータセンターに設置され、専用のネットワーク機器を介して緊密に結合されています。これにより、GPU間の通信が非常に効率的に行われるようになります。これらのGPUでは、1秒あたりに数テラバイトのデータをやり取りする必要があるため、効率的な通信は極めて重要です。モデルの規模がさらに何兆ものパラメータにまで拡大すると、GPU間でやり取りされるデータ量もそれに比例して増加します。
これが、何十億ドルもの資金がGPUの取得やAI専用データセンターの構築に費やされている理由です。LLMのパフォーマンスにおいても、規模の法則が当てはまります。より大きなモデルは、より大規模なレベルのデータと演算を必要としますが、一般的に、より小さな先行モデルよりも優れたパフォーマンスを発揮します。
分散型コンピューティング
前述の通り、GPU間の大量の通信が必要であるため、GPUを同じ場所に配置する必要があります。この特性は、特にAI x クリプト分野において、純粋な集中型トレーニングモデルから、より分散型または分散型のモデルに移行しようとしているチームにとって、大きな制約となっています。
多数のチームが、分散型コンピューティングへのアクセスポイントまたはプロバイダーとしての地位を確立しています。簡単に言えば、この分野のほとんどのプロジェクトは、NVIDIAの3090や4090などのコンシューマー向けやゲーム向けのGPUから、NVIDIAのA100やH100などのハイエンドのML専用GPUまで、さまざまなGPUサプライヤーを惹きつけようとしています。一般的に、これらのネットワークはGPUコンピューティングの価格を低く設定しており、これは分散型GPUネットワークの主な付加価値の1つです。
しかし、これらのGPUネットワークの多くは特定の用途に特化しておらず、汎用GPUコンピューティングのためのプラットフォームを提供しています。これに対し、GenSynやPrime Intellectなどのチームは、MLモデルのトレーニングに特化したプラットフォームの開発を目指しています。前述の通り、分散型または非集中型のトレーニングの進捗を妨げる主な制約は、GPU間の通信オーバーヘッドです。しかし、Prime Intellectは7月10日、非集中型トレーニングの新しいアプローチについて説明した論文を発表しました。
Prime Intellectと分散型トレーニング
GoogleのDeepMind研究所によるオリジナルの研究をオープンソース化し、さらに拡張した論文の中で、Prime Intellectは、分散型低通信(DiLoCo)手法を用いた分散型トレーニングを実施しています。
DiLoCoのトレーニング方法は、一般的な集中型トレーニング設定で頻繁に見られるような通信の必要性を排除することで、GPUの通信制約を緩和します。各トレーニングステップの後にGPU間でデータを転送する代わりに、より多くのトレーニングステップをローカルで継続的に行い、一定量のトレーニングデータが処理された後に、GPUネットワーク全体で定期的に通信を行います。
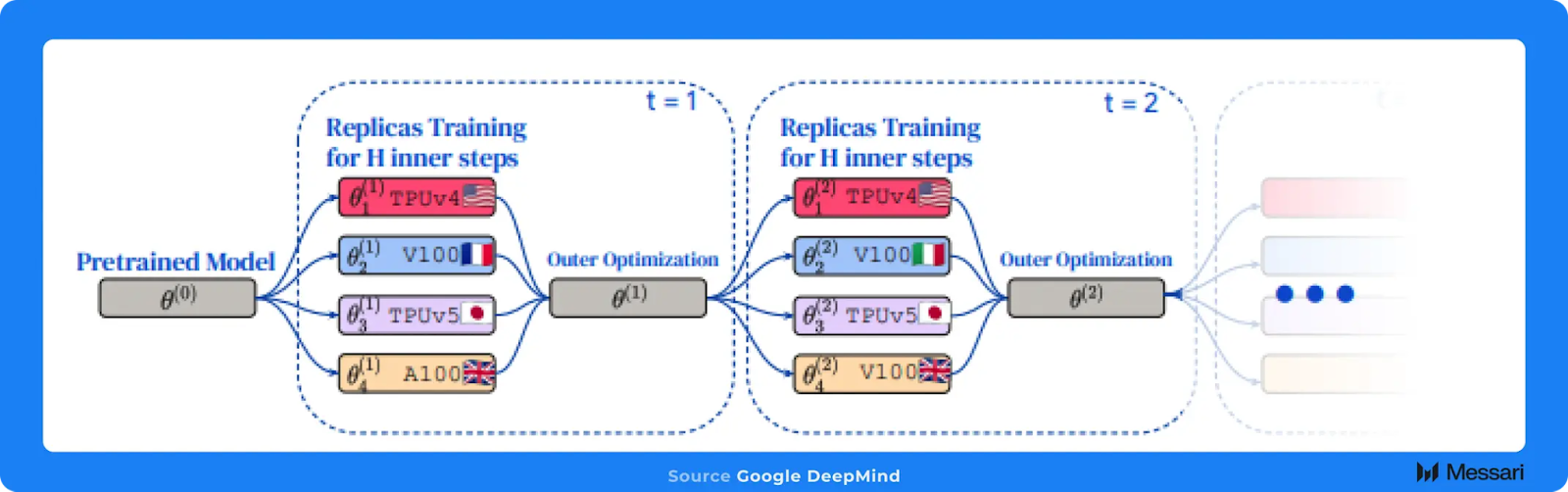
実験を通じて、研究チームは、同じコンピューティング予算で、集中型でトレーニングしたモデルのパフォーマンスに匹敵する効果を上げられることを示しました。その代わりに、H100を4つの地理的に分散したクラスターで使用し、集中型セットアップよりも125分の1の通信量で実行しました。DeepMindのオリジナルの研究では、DiLoCoを5億パラメータのモデルで実行しましたが、Prime Intellectでは、11億パラメータのモデルを使用することで、研究におけるモデルサイズを効果的に2倍にしました。
コンピューティングの枠を超えて:機械学習の研究と人材
Prime Intellectチームの成果は、分散型トレーニングコミュニティの限界を押し広げ、この分野における継続的な研究の足がかりとなるでしょう。一般的に、DiLoCoが示したような新しいモデルアーキテクチャやトレーニング方法は、集中型市場を凌駕し、あるいはそれに匹敵するものとなるためには、引き続き実験を重ねる必要があります。
この実験から得られる最もポジティブな成果は、現状からの根本的な転換を意味するでしょう。モデルは、必ずしもより大規模なモデルに後ろ盾となるより多くのコンピューティングパワーを配置するのではなく、分散コンピューティングネットワークを活用するように設計される可能性があります。分散型AI分野では、モデルやアルゴリズムレベルでのこのようなイノベーションを継続的に推進していくために、より多くのトップクラスの機械学習人材を惹きつける必要があるでしょう。
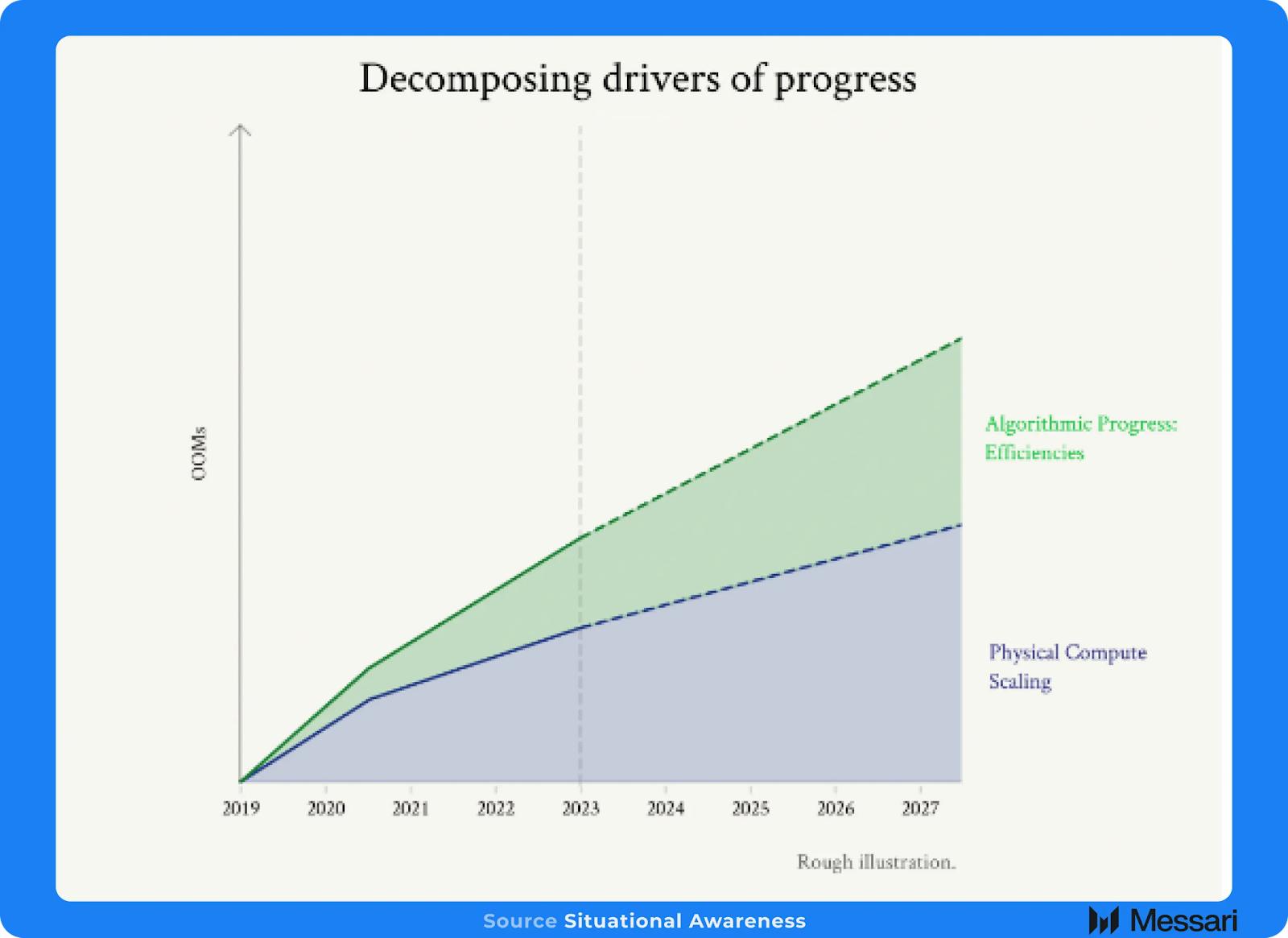
これまで、より強力なGPUをより大きなモデルに活用するといった単純な拡張(brute force scaling)によってフロンティアモデルは前進してきましたが、今後はアルゴリズムの革新がより大きな役割を果たすことになるでしょう。この層における画期的な進歩は、研究者がトレーニングデータの管理と作成に新しい手法を活用すること(例えば、合成データの新しい利用法など)や、モデルアーキテクチャやトレーニング技術の実験から生まれるでしょう。例えば、Metaは、最近リリースされたLlama 3.1モデルの開発において、合成データの効果的な利用が重要な要素であったと指摘しています。
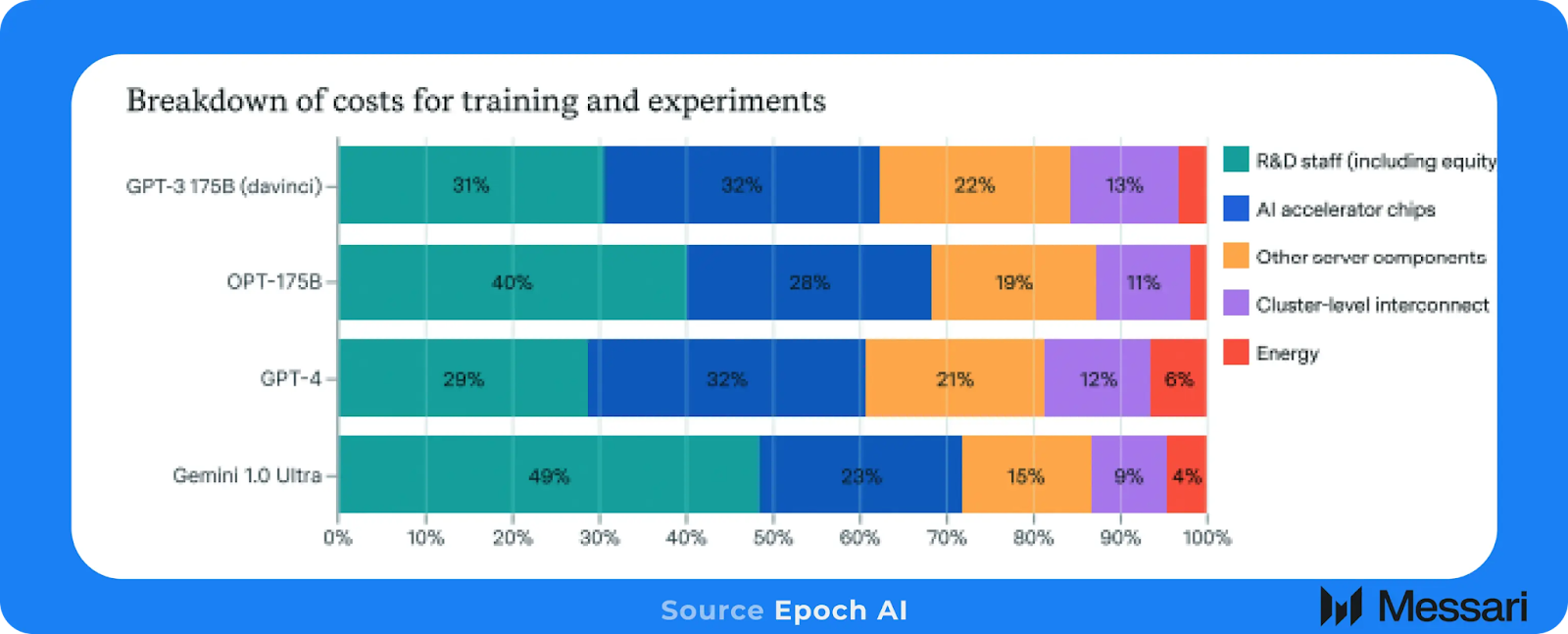
Epoch AIは最近、最先端モデルのトレーニングにかかる総コストの30%から50%がML研究スタッフの人件費であると推定しました。この数字は、一般的にモデルのトレーニングに関する議論のほとんどが、追加のコスト要素ではなく、純粋なコンピューティングとGPUの費用に焦点を当てているため、やや意外です。モデルのトレーニングにかかる膨大な総コストを考えると、多くのML研究者はすでに経済的な安定を確保しており、今後は経済的な動機が弱まる可能性があることを意味します。
金銭的な観点に加えて、クローズドソース vs オープンソースのAIを巡る議論が激化し、より現実的な懸念事項となるにつれ、ML研究者の倫理的な不満がさらに高まる可能性があります。
金銭的な動機付けの欠如とオープンソースコミュニティへの貢献の魅力が相まって、集中型でクローズドソースのAIラボから人材が移行する上で、必要不可欠な触媒として機能する可能性があります。
オープンソースAIの調整
リソースの割り当てや一般的な調整は、集中型のAI企業内でははるかにシンプルになることがよくあります。 通常、指令はトップダウン方式で伝えられ、企業の努力は厳格かつ集中的に維持されます。 幅広いステークホルダーとともにオープンな環境でAIシステムを成功裏に開発するには、適切なインセンティブとインフラが必要です。
Bittensorは、この大型のオープンソースAI開発と調整のビジョンに向けて構築された最も初期のチームのひとつです。全体として、Bittensorは、それぞれが異なるAI目標に焦点を当てた個々のネットワークのエコシステムと見なすことができます。この観点から、Bittensorは、様々な目的に役立つあらゆるAIモデルの実験を行うための広範な水平的実験場という、当社が見据える分散型AIのチャンス分野にうまく適合します。
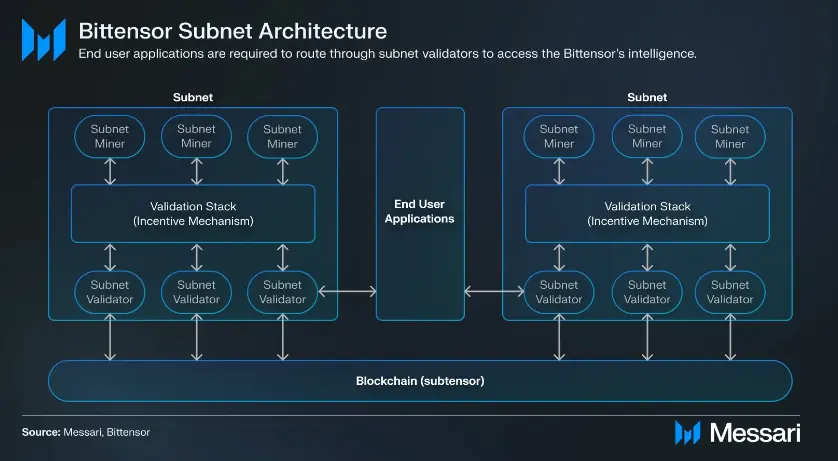
Bittensorネットワーク、別名サブネットには、そのサブネットの目標を設定するオーナーがいます。サブネット上のマイナーはAIエンジニアのような存在で、サブネットのオーナーが設定したタスクを完了させる責任があります。サブネットのバリデーターは、別個のグループで、「バリデーションスタック」を実行し、最も優れたパフォーマンスを発揮しているマイナーを効果的に証明します。BittensorのネイティブトークンであるTAOは、各サブネットに発行され、サブネットのオーナーが設定したAIタスクを完了させるためのインセンティブとして機能します。
Bittensorは、複数の研究チームやアプリケーション開発者をネットワークに引きつけています。Nous Researchは、Bittensorのサブネットの開発と活用に取り組んだ研究志向のチームの1つでしたが、その後、ネットワークから離脱しました。同チームは、オープンソースのHermes LLM(MetaのLlamaモデルを微調整したモデル)を構築するための巧妙な戦略を持っていました。
- あるサブネットでは、マイナーはOpenAIのGPT-4などの最先端モデルから推論出力を生成し、保存するという効果的なタスクを担っていました。
- これらの出力は、マイナーがHermes LLMを微調整する他のサブネット用の合成データとして使用されました。
- どのHermesモデルが最高のパフォーマンスを発揮したかを評価するために、バリデータはGPT-4の合成データをベンチマークとして使用し、Hermesサブネット上の各マイナーを評価しました。Hermesの出力がGPT-4に近ければ近いほど、Hermesモデルは優れているとみなされます。したがって、漸近的には、HermesモデルはGPT-4の品質に近づくはずです。
Bittensor の主な利点の1つは TAOトークンの排出であり、これは上記のプロセスに関連する推論コストへの補助金と見なすことができます。
Nousのオリジナルの研究以来、多数の他のチームがBittensorエコシステムを活用して、特定のアプリケーションや商品を開発しています。ロールプレイングサブネットを備えたDippyは、その代表的な例です。商品としては、DippyはAIコンパニオンアプリケーションであるCharacter.aiに匹敵します。チャットアシスタントとしての位置付けが強いchatGPTとは異なり、DippyのロールプレイングLLMには、異なる性格や特徴が必要です。マイナーはLLMの微調整をテストすることができ、TAOの発行を通じてインセンティブが与えられるため、このシナリオにはBittensorの設計が適しています。
Bittensorには問題がないわけではなく、克服すべき課題もいくつかありますが、「インセンティブ・アズ・ア・サービス」という設計は多くのチームにとって魅力的であることが判明しています。そのため、AI x クリプトスタックのこのレイヤーで、さらに多くのプロジェクトが立ち上がることを期待しています。具体的には、Bittensorとは異なり、チームはより垂直統合型の構築を目指し、Bittensorのようなネットワーク上で展開およびテストされたモデルを同じシステム内で商品化できる可能性があります。現在、Bittensorを基盤とするアプリケーションのエンドユーザーは、これらのサービスにアクセスするためにTAOトークンを支払う必要がないため、Bittensorベースのアプリケーションの成長に比例してBittensorの価値が拡大する仕組みが欠如しています。この仕組みが確立されれば、理論上はエコシステムから流出する価値が少なくなるため、より強固な競争優位性を確立できるでしょう。
クローズドソースの集中型AI企業と比較すると、Bittensorおよび類似プロジェクトは、実験の最適化やモデルの迅速な出荷・調整が可能です。AIラボの最大手企業が活用する巨大なスケールメリットに対抗し、競争することは、短期的には勝ち目のない戦いでしょう。そのため、DippyのロールプレイングLLM、タンパク質フォールドモデル、取引モデル、その他のユースケースなど、Bittensorのような連携ネットワークは、このような多種多様なMLアプリケーションの試験場としてのポテンシャルを最大限に活用することを目指すべきです。
オンチェーン領域の探索
ブロックチェーンのようなパーミッションレスのオープンネットワークでは、日々新しいクリプトトークン、商品、アプリケーションが立ち上げられています。集権型の登録機関や「App Store」が存在しないため、オンチェーンの参加者がこうした新しい展開を発見し、精査することは、膨大な作業となります。発見した後でも、新しいアプリケーションを操作するためのトークンやツールを取得することは大きな参入障壁となり、潜在的な新規参入者を遠ざける可能性があります。
Wayfinder:アプリケーションの発見と意思の実行
Colony ゲームを開発している Parallel チームは、こうした課題の多くに対処するために、Wayfinder プロトコルを開発しました。 Wayfinder は、オンチェーンアプリケーションをグラフ構造に効果的にマッピングすることで、変化し続けるブロックチェーン環境を安全に横断できるような世界を目指しています。
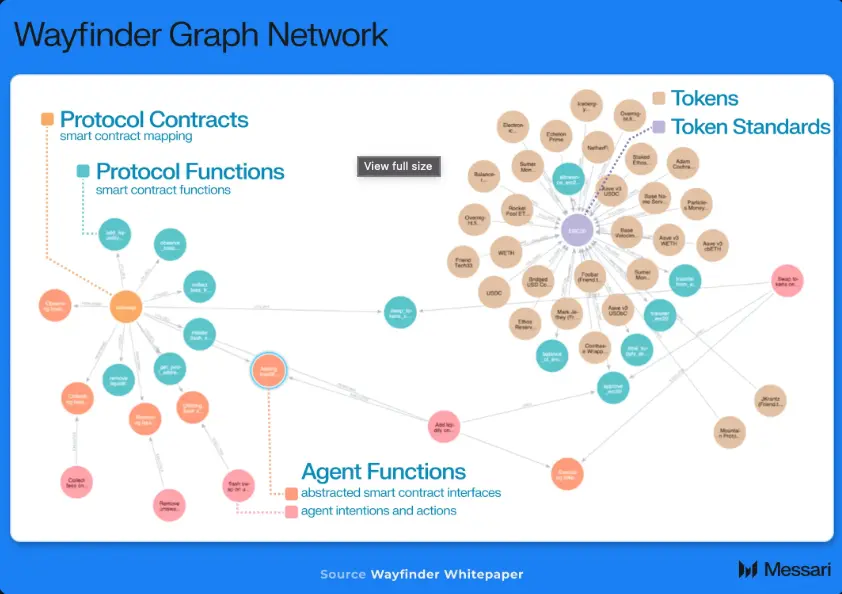
AIエージェント、またはWayfinderの用語では「shell」は、このグラフ構造の頂点に位置し、ユーザーに代わって行動します。このグラフ構造は、shellがオンチェーンアプリケーションと最適に操作する方法を導き出すためのコンテキストと「経路」を構築します。概念的には、この設計はアプリケーションの発見とIntentの実行を単一のプロトコルに統合します。例えば、ユーザーはWayfinderに、OptimismでETHをUSDCに交換する最適経路を見つけるよう指示することができ、WayfinderのAIエージェントが最適な経路を計算し、必要な取引ペイロードを作成し、取引を実行します。
開発者がWayfinderのネイティブトークンであるPROMPTを経路に対して担保することで、新しいアプリケーションをWayfinderのグラフネットワークの経路として追加することができます。Wayfinderに新しい経路を追加することで、
- PROMPTトークンの需要が増加
- 経路が誤って設定されていたり、明らかに悪意ある目的で設定されている場合、PROMPTがスラッシュされる可能性があるため、「リスクの共有」が生じる
- すべてのユーザーが経路を活用し始めるため、ネットワークの価値が向上します。
Wayfinderは、その本質において、開発者が提供し担保するアプリケーションやコードをAIエージェントが活用する動的な取引市場としての役割を果たします。
Wayfinderの競合優位性をグラフ化
クリプト空間において堀を築き、守ることは非常に困難です。しかし、Wayfinderプロトコルから明確な推進力が生まれる可能性があります。
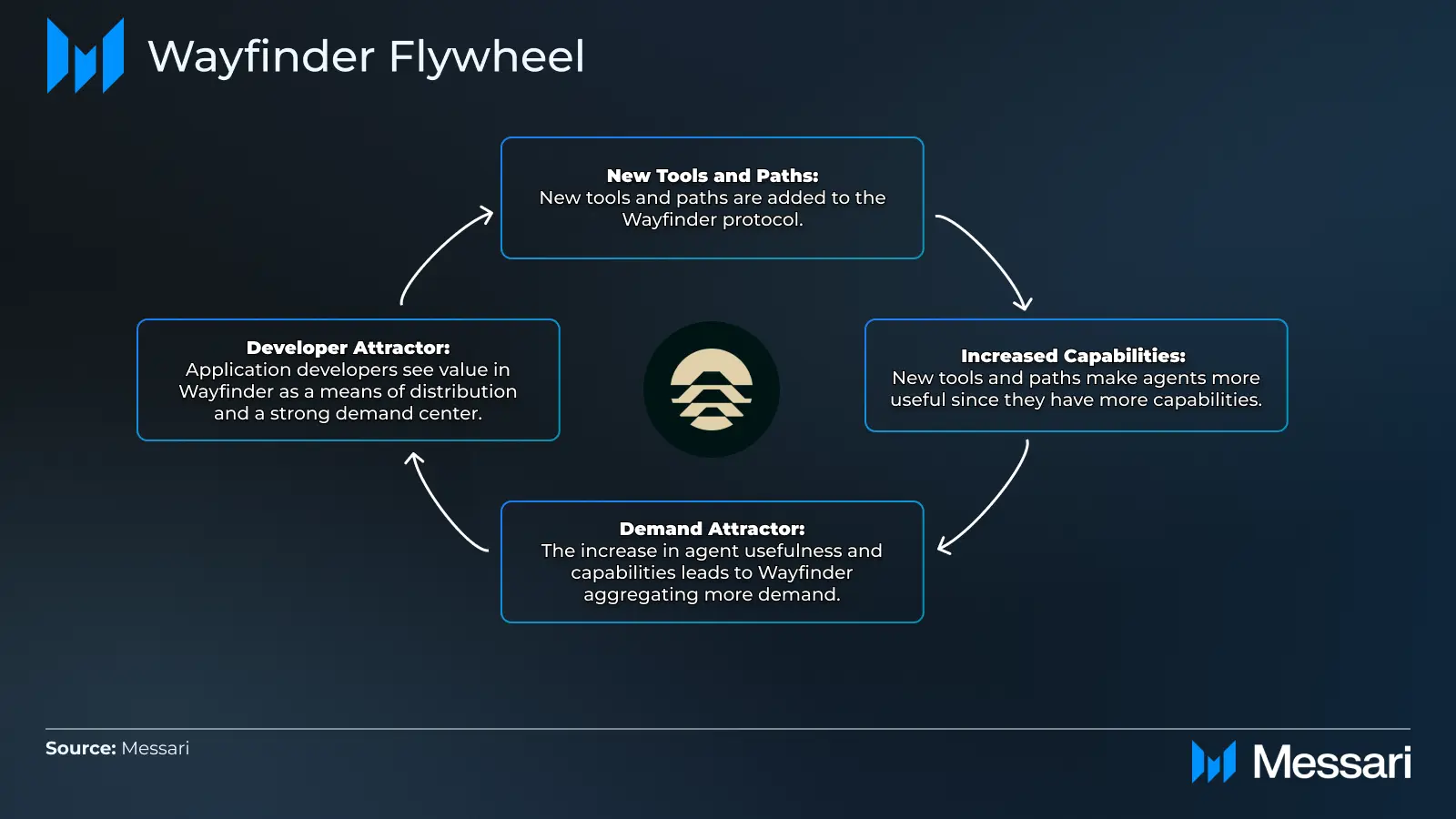
AIエージェントの機能は、Wayfinderに追加される新しいツールや経路とともに向上します。エンドユーザーの視点では、これは単一のインターフェースに集約された新しいアプリケーションを探索する機会を生み出します。WayfinderのAIエージェントに需要が集中するにつれ、開発者はこれを活用して、広範で成長を続けるユーザー層にアプリケーションを配布することができます。
Wayfinderは、初期段階では、社内開発のAIエージェント、パス、および一般的なツールの小規模なセットをプロトコルの種として使用する可能性が高いでしょう。例えば、初期のエージェントセットは、EthereumメインネットからBaseなどのL2にユーザーのトークンをブリッジし、その後、Base DEXでトークン交換を実行できる可能性が高いでしょう。
最終的には、このネットワークがユーザーや開発者に対して、独自のモデルの導入を促し、さらには特定の設計による新しいAIモデルの開発を奨励することになるかもしれません。Dustin Teander氏が指摘したように、Bittensorはこの仕組みの最有力候補となる可能性があります。WayfinderがBittensorをこのような形で活用する最初の事例となるわけではありません。AIコンパニオンアプリケーションのMyshellは、Bittensorサブネットを介してテキスト音声変換モデルの開発を奨励しています。
Autonolas:AIツールと機能のマーケットプレイス
AI x クリプトの交差点におけるAIエージェント層に焦点を当てた初期のプロジェクトの1つがAutonolasです。開発者は、Open Autonomyフレームワークを使用してAIエージェントを作成でき、そのAIエージェントはNFTとして発行できます。これにより、他の開発者はそれぞれのエージェントサービスで各コンポーネントを再利用できます。
Autonolasシステム内のエージェントは、適切なツールやスキルを装備してタスクや目的を達成するために、Mechを活用することができます。Mechシステム全体は、以下の要素で構成されています:
- 特定のMechを制御するオフチェーンのAIエージェントの集団、MechはNFTとしてオンチェーンの足跡も残す
- Mechのレジストリとして機能するオンチェーンのスマートコントラクトのセット
- ユーザーが利用可能なMechを確認し、それを操作できるフロントエンド
- Mechサービスの支払いには、単発のオンチェーン決済、またはNevermined経由で設定されたサブスクリプションサービスを利用できます
例えば、AutonolasのAIエージェントの現在の主なユースケースの1つは、予測市場での取引です。Autonolasシステム内では、AIエージェントはMechレジストリ内の「prediction_request」ツールを使用できます。このMechツールは、GoogleとOpenAIのAPIを使用して、特定の市場(例えば、米国大統領選挙)に関連するニュースや時事問題を収集し、特定の予測市場で賭けを行うかどうかについての回答を生成します。
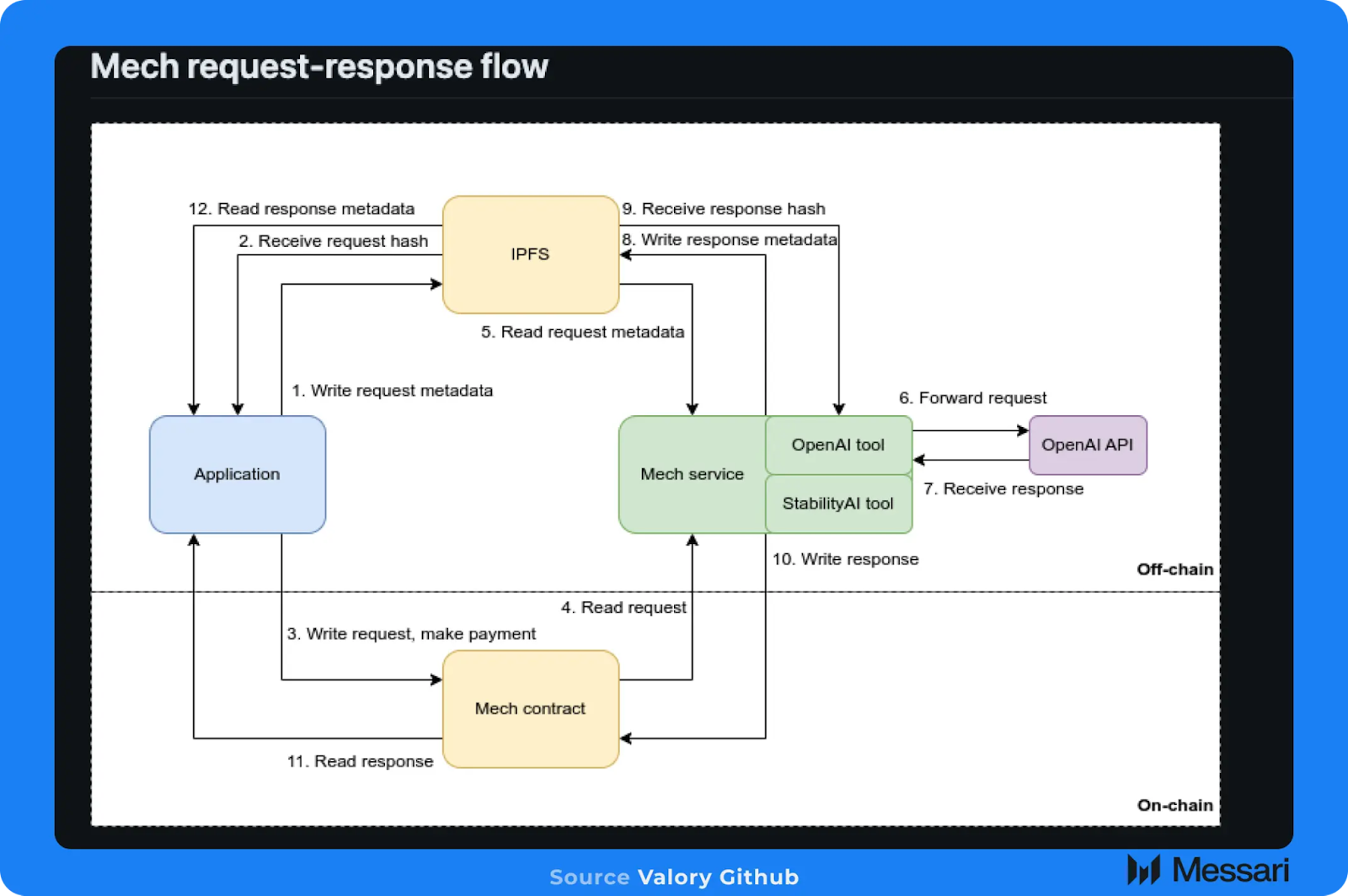
エージェント開発者がこれらのサービスの両方でAPIキーを管理し、応答を処理する必要がない代わりに、既存のMechツールがパッケージ化されて提供されており、ユーザーに代わってこれらのタスクを実行します。
AutonolasとWayfinderは、どちらも一般的に、エージェントがオンチェーンのメカニズムでタスクを完了するためのシステムを構築しています。AutonolasはMech設計を活用しており、WayfinderはGraph Networkと隣接するツールやスキルを使用しています。しかし、AutonolasのMechの設計はWayfinderのグラフネットワークとは若干異なります。Wayfinderに組み込まれた賞金システムは、新しい経路を即座に作成するインセンティブを与えるという点で有利であり、経路の担保メカニズムにより、経路が適切に管理・維持されることが保証されます。
AIエージェント:オンチェーン参加者の新たなクラス
Wayfinder、Autonolas、そして数多くの他のAIエージェントプロトコルが指し示す大きなテーマは、AIエージェントのオンチェーン活動の急増です。前述の通り、これはAIとクリプトの交差する2つ目の領域であり、AIがクリプトネットワーク上で経済活動を生成することで、クリプトのマスアドプションを加速します。
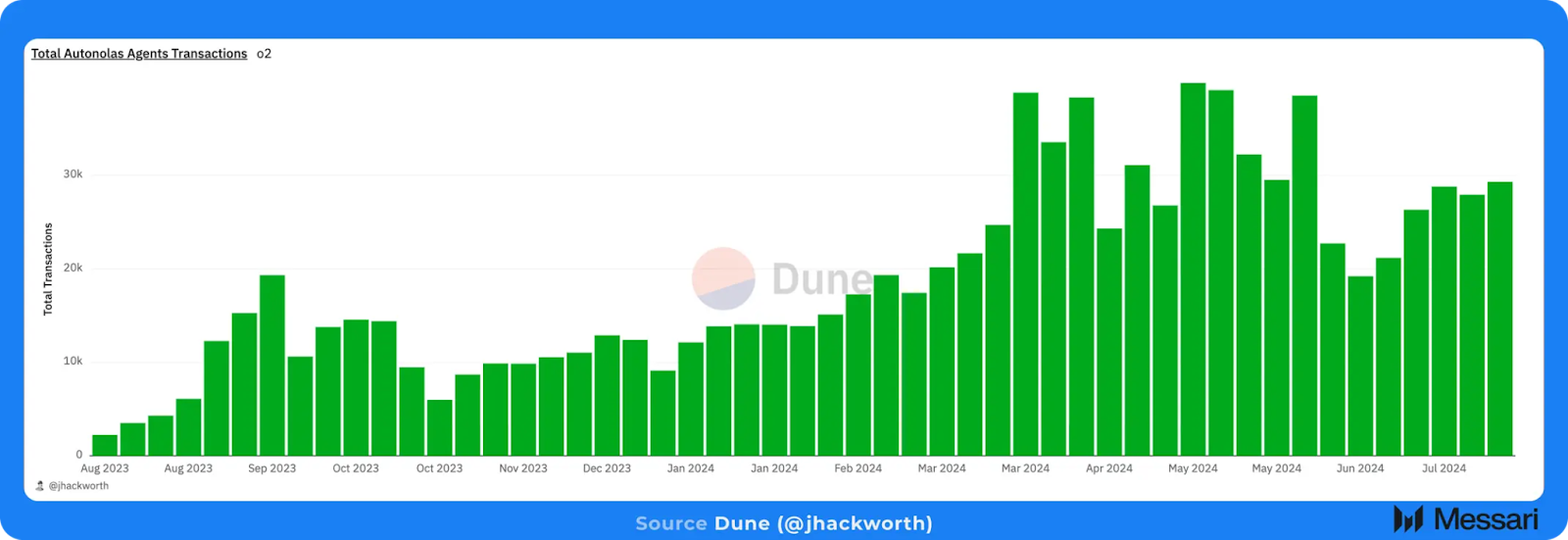
完全に自律したAIエージェントがオンチェーンで稼働する段階はまだ初期段階ですが、WayfinderやAutonolasのようなシステムにさらに多くの機能や性能が追加されるにつれ、このグラフは上昇し、右肩上がりに推移していくと予想されます。
AIエージェントの主な利点のひとつで、人間ユーザーにはまだ十分に理解されていないものに、複合的ナレッジ効果があります。エージェントは、ナレッジ(知識)を明確なコードブロックとして保存します。これにより、エージェントが生成する知識や行動は構造化され標準化され、必要に応じて実行や参照が可能になります。この特性こそが、Wayfinderのようなプロトコルを非常に価値あるものにしているのです。Wayfinderプロトコルに新しい経路、すなわちコードが追加されるたびに、プロトコルに接続しているすべてのエージェントが即座にその経路を活用し、既存のツールセットに追加することができます。
もちろん人間はこのような方法で動きません。人間の知識は、コードのブロックのように拡張したり普及したりすることはありません。コードとAIエージェントに関連するより広範な規模と収益化の手段により、オンチェーンエコシステムに参加するエージェントがますます増えていくことが予想されます。
分散型AIの今後の展望
AI x クリプト分野はまだ初期段階ですが、新たなチームが資金調達を行い、より確立されたチームが商品と市場の適合を目指して取り組むことで、成長は続くと考えられます。
特に、AI x クリプトスタックの下層(すなわち、コンピューティングプロバイダーやモデル開発者)を構築するチームは、分散型コンピューティング環境により適切にマッピングできる、異なる、より小規模なモデル設計の実験に重点的に取り組む必要があるでしょう。
一方、クリプトネットワークやアプリケーションは、新しいオンチェーンのユーザー集団を代表するものとして、AIエージェントの商業化から恩恵を受けるはずです。WayfinderやAutonolasのようなチームが現在、最前線に立っていますが、多数の他のチームも「エージェントネットワーク」の開発に取り組んでおり、Messariでは近い将来、この分野をさらに深く掘り下げていくことになるでしょう。
AIがクリプトを加速させるか、あるいはその逆になるかに関わらず、この2つの分野の交差点は、今後数年間で指数関数的に発展するテクノロジーの最も興味深い組み合わせの1つであり続けるでしょう。
*元の記事は2024年8月1日執筆です。記事中のデータは現時点の数値と乖離している可能性がございます、予めご了承ください。